Bạn có bao giờ thắc mắc làm thế nào để “chỉ đường” cho Google trên website của mình chưa? Robots.txt là gì mà lại được xem như “người gác cổng” thầm lặng, quyết định con bot nào được vào, khu vực nào bị cấm? Hiểu và sử dụng file này đúng cách là chìa khóa để tối ưu SEO hiệu quả. Hãy cùng WiWeb tìm hiểu từ A-Z cách tạo và tối ưu file robots.txt một cách chuyên nghiệp nhất nhé!
Robots.txt là gì?
Hãy tưởng tượng website của bạn là một tòa nhà lớn với nhiều phòng ban. Các công cụ tìm kiếm như Google, Bing sẽ cử những con “bot” (còn gọi là spider hoặc crawler) đến để khám phá và ghi nhận thông tin từ tòa nhà này.
File robots.txt chính là tấm biển chỉ dẫn đặt ngay ở cổng chính. Nó là một tệp văn bản đơn giản, có tên là robots.txt, nằm ở thư mục gốc của website. Tấm biển này đưa ra những quy tắc, chỉ dẫn cho các con bot biết phòng nào chúng được phép vào xem, và phòng nào là khu vực riêng tư không nên vào.
Nói một cách kỹ thuật, robots.txt là một phần của Giao thức Loại trừ Robot (Robots Exclusion Protocol). Đây là một bộ tiêu chuẩn web quy định cách các bot tự động thu thập thông tin trên web. Điều quan trọng cần nhớ: đây là những chỉ dẫn, không phải là mệnh lệnh bắt buộc. Các bot “ngoan” như Googlebot sẽ tuân thủ, nhưng các bot xấu có thể phớt lờ nó.
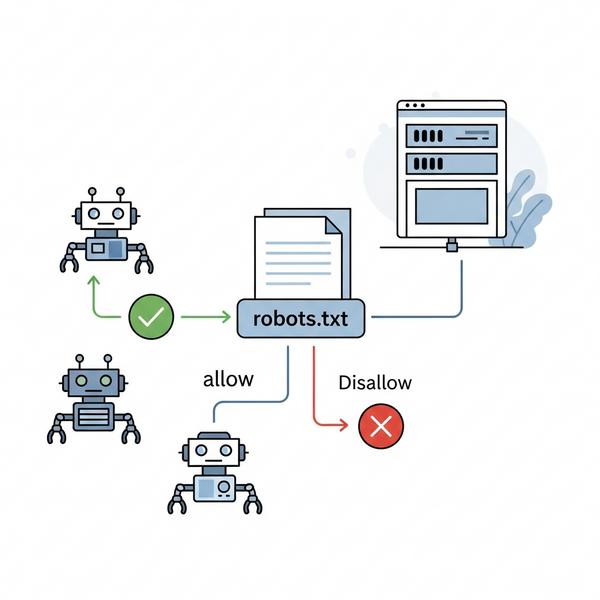
File robots.txt có tác dụng gì và tại sao lại quan trọng với SEO?
Một file văn bản nhỏ bé nhưng lại có sức ảnh hưởng rất lớn đến hiệu suất SEO của website. Vậy chính xác thì nó giúp bạn làm được gì? Về cơ bản, file robots.txt là công cụ đắc lực giúp bạn giao tiếp và điều hướng các bot tìm kiếm một cách thông minh.
Quản lý ngân sách thu thập dữ liệu (Crawl Budget) hiệu quả
Mỗi website đều có một “ngân sách thu thập dữ liệu” (Crawl Budget) nhất định. Đây là số lượng trang mà Googlebot sẽ thu thập trong một khoảng thời gian. Nếu website của bạn có hàng ngàn trang nhưng ngân sách lại có hạn, bot có thể lãng phí thời gian vào những trang không quan trọng (như trang quản trị, trang cảm ơn, kết quả tìm kiếm nội bộ).
Bằng cách dùng robots.txt để chặn các khu vực này, bạn đang giúp Googlebot tập trung toàn bộ “ngân sách” vào việc thu thập dữ liệu các trang quan trọng nhất. Điều này giúp nội dung chất lượng của bạn được phát hiện và index nhanh hơn.
Ngăn chặn công cụ tìm kiếm lập chỉ mục các trang không mong muốn
Không phải trang nào trên website cũng nên xuất hiện trên kết quả tìm kiếm. Ví dụ như các trang đang trong giai đoạn phát triển, các file PDF nội bộ, hay các trang có nội dung trùng lặp. File robots.txt giúp bạn ngăn các bot này truy cập vào những URL đó ngay từ đầu.
Lưu ý rằng, robots.txt chỉ ngăn việc thu thập dữ liệu, không phải ngăn việc lập chỉ mục một cách tuyệt đối. Nếu một trang bị chặn trong robots.txt nhưng lại có liên kết từ nơi khác, Google vẫn có thể lập chỉ mục URL đó mà không có nội dung. Để chắc chắn một trang không được index, bạn nên kết hợp với thẻ meta noindex.
Chỉ dẫn đường cho bot đến sơ đồ trang web (Sitemap)
Đây là một chức năng cực kỳ hữu ích. Thay vì để bot phải tự tìm kiếm sơ đồ trang web (Sitemap), bạn có thể khai báo sitemap trong robots.txt. Việc này giống như bạn đưa cho người khách một tấm bản đồ toàn bộ tòa nhà ngay tại cổng. Bot sẽ biết chính xác các URL quan trọng bạn muốn chúng lập chỉ mục, giúp quá trình thu thập dữ liệu diễn ra nhanh chóng và đầy đủ hơn.

Cách hoạt động của file Robots.txt
Quy trình hoạt động của file robots.txt rất logic và dễ hiểu. Khi một bot của công cụ tìm kiếm ghé thăm website của bạn, nó sẽ thực hiện các bước sau:
- Tìm kiếm file robots.txt đầu tiên: Trước khi thu thập dữ liệu bất kỳ trang nào, bot sẽ tìm đến địa chỉ
yourdomain.com/robots.txt. - Đọc các quy tắc: Nếu tìm thấy file, bot sẽ đọc nội dung bên trong để xem có quy tắc nào dành cho nó không.
- Tuân thủ chỉ dẫn: Bot sẽ đối chiếu URL nó định thu thập với các lệnh trong file. Nếu URL bị chặn bởi lệnh
Disallow, nó sẽ bỏ qua. Nếu được phép bởi lệnhAllowhoặc không có quy tắc nào, nó sẽ tiếp tục thu thập dữ liệu. - Nếu không có file robots.txt? Trong trường hợp không tìm thấy file này, bot sẽ mặc định rằng nó được phép thu thập dữ liệu của toàn bộ website. Điều này không hẳn là xấu, nhưng bạn sẽ mất đi quyền kiểm soát quý giá.
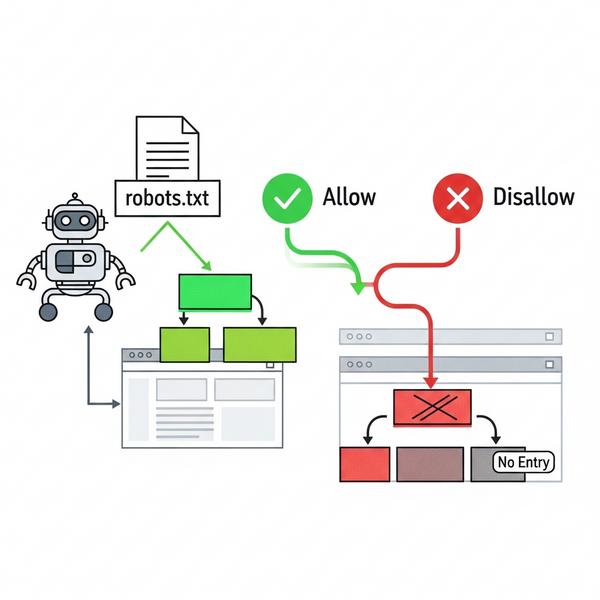
Tìm hiểu cú pháp và các lệnh cơ bản trong Robots.txt
Để viết được một file robots.txt hiệu quả, bạn cần nắm vững cú pháp file robots.txt. Đừng lo, nó khá đơn giản và chỉ xoay quanh một vài lệnh chính. Mỗi quy tắc trong file thường bao gồm hai phần: User-agent (đối tượng áp dụng) và các lệnh Disallow hoặc Allow (hành động).
User-agent: Chỉ định bot áp dụng quy tắc
Lệnh này dùng để xác định con bot cụ thể mà bạn muốn ra chỉ thị. Mỗi công cụ tìm kiếm có một user-agent riêng (ví dụ: Googlebot, Bingbot).
- Để áp dụng quy tắc cho tất cả các bot, bạn dùng dấu sao:
User-agent: *. - Để áp dụng cho riêng bot của Google, bạn dùng:
User-agent: Googlebot.
Disallow: Lệnh không cho phép truy cập
Đây là lệnh phổ biến nhất, yêu cầu bot không được thu thập dữ liệu một URL hoặc một thư mục cụ thể. Giá trị của Disallow phải bắt đầu bằng dấu /.
- Chặn toàn bộ website:
Disallow: / - Chặn một thư mục:
Disallow: /wp-admin/(chặn tất cả URL bắt đầu bằng/wp-admin/) - Chặn một trang cụ thể:
Disallow: /trang-ca-nhan.html
Allow: Lệnh cho phép truy cập
Lệnh Allow cho phép bot truy cập vào một tệp hoặc thư mục con ngay cả khi thư mục cha của nó đã bị chặn. Lệnh này có độ ưu tiên cao hơn Disallow.
Ví dụ: Bạn muốn chặn toàn bộ thư mục /media/ nhưng lại muốn cho phép bot truy cập file /media/public.jpg bên trong. Bạn sẽ viết như sau:
User-agent: *
Disallow: /media/
Allow: /media/public.jpg
Sitemap: Khai báo vị trí sơ đồ trang web
Lệnh này không phụ thuộc vào User-agent và thường được đặt ở cuối file. Nó chỉ đơn giản là chỉ cho bot biết vị trí của sitemap XML.
Cú pháp: Sitemap: https://yourdomain.com/sitemap_index.xml
Crawl-delay: Thiết lập độ trễ giữa các lần thu thập dữ liệu
Lệnh này yêu cầu bot phải chờ một khoảng thời gian nhất định (tính bằng giây) trước khi thu thập dữ liệu trang tiếp theo. Mục đích là để giảm tải cho máy chủ. Tuy nhiên, Googlebot hiện không còn hỗ trợ lệnh này. Thay vào đó, bạn có thể thiết lập tốc độ thu thập dữ liệu trong Google Search Console.

Hướng dẫn chi tiết cách tạo file Robots.txt
Bây giờ chúng ta sẽ đi vào phần thực hành. Cách tạo file robots.txt vô cùng đơn giản, bạn chỉ cần làm theo 3 bước sau.
Bước 1: Tạo một file văn bản mới có tên ‘robots.txt’
Bạn có thể sử dụng bất kỳ trình soạn thảo văn bản nào có sẵn trên máy tính, ví dụ như:
- Notepad trên Windows
- TextEdit trên macOS
Quan trọng nhất là khi lưu file, bạn phải đặt tên chính xác là robots.txt, viết bằng chữ thường và không có bất kỳ ký tự hay phần mở rộng nào khác.
Bước 2: Thêm các quy tắc vào file
Dựa vào các cú pháp chúng ta đã tìm hiểu ở trên, bạn hãy viết các quy tắc phù hợp với cấu trúc website của mình. Một file robots.txt cơ bản cho website WordPress có thể trông như sau:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://yourdomain.com/sitemap_index.xml
Bước 3: Đặt file robots.txt ở đâu?
Đây là bước quyết định. File robots.txt chỉ có hiệu lực khi được đặt đúng vị trí. Bạn cần upload file này lên thư mục gốc (root directory) của website. Thư mục này thường có tên là public_html, www, hoặc htdocs tùy vào nhà cung cấp hosting.
Sau khi upload, bạn có thể kiểm tra bằng cách truy cập vào đường dẫn https://yourdomain.com/robots.txt. Nếu nội dung file hiện ra, bạn đã làm đúng!
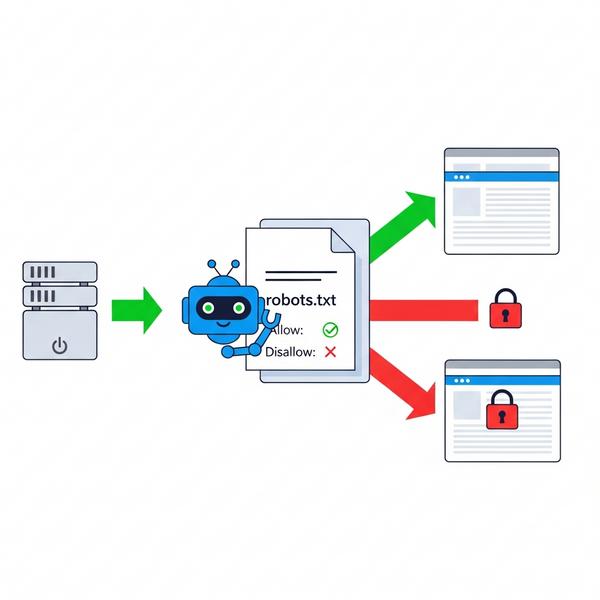
Các ví dụ về file Robots.txt cho những trường hợp phổ biến
Dưới đây là một vài mẫu file robots.txt bạn có thể tham khảo và tùy chỉnh cho website của mình.
Mẫu file robots.txt cho phép tất cả
File này báo cho tất cả các bot rằng chúng được phép thu thập dữ liệu toàn bộ website. Nếu bạn không có file robots.txt, các bot cũng sẽ tự hiểu theo cách này.
User-agent: *
Disallow:
Mẫu file robots.txt chặn tất cả
File này ngăn không cho bất kỳ bot nào thu thập dữ liệu trên website. Hữu ích khi website đang trong giai đoạn xây dựng và bạn không muốn nó xuất hiện trên Google.
User-agent: *
Disallow: /
Mẫu file robots.txt chặn một thư mục cụ thể
Trong ví dụ này, chúng ta chặn không cho các bot truy cập vào thư mục cgi-bin và private.
User-agent: *
Disallow: /cgi-bin/
Disallow: /private/
Mẫu file robots.txt tối ưu cho WordPress
Đây là một hướng dẫn tạo file robots.txt chuẩn SEO cho nền tảng WordPress. Nó chặn các khu vực không cần thiết như trang quản trị, file mã nguồn nhưng cho phép truy cập các tài nguyên quan trọng để Google có thể hiển thị trang của bạn một cách chính xác. Đây là một cấu hình robots.txt for wordpress rất phổ biến.
User-agent: *
# Chặn các thư mục cốt lõi của WordPress
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /readme.html
# Cho phép file ajax để các chức năng hoạt động
Allow: /wp-admin/admin-ajax.php
# Khai báo sitemap
Sitemap: https://yourdomain.com/sitemap_index.xml

Cách kiểm tra và tối ưu file Robots.txt chuẩn SEO
Sau khi tạo và upload file, bước tiếp theo là kiểm tra để đảm bảo nó hoạt động đúng như ý muốn và không vô tình chặn các nội dung quan trọng. Đây là bước quan trọng để tối ưu file robots.txt.
Sử dụng công cụ kiểm tra robots.txt của Google Search Console
Google cung cấp một công cụ kiểm tra robots.txt miễn phí và cực kỳ mạnh mẽ ngay trong Google Search Console. Công cụ này giúp bạn:
- Xem phiên bản file robots.txt mà Google đang sử dụng.
- Kiểm tra xem một URL cụ thể có đang bị chặn hay không.
- Phát hiện các lỗi cú pháp hoặc logic trong file.
Để sử dụng, bạn chỉ cần truy cập vào công cụ, chọn website của mình và nhập URL bạn muốn kiểm tra. Kết quả sẽ cho biết URL đó được phép (Allowed) hay bị chặn (Blocked) bởi quy tắc nào.
Các lỗi thường gặp và cách khắc phục nhanh chóng
- Chặn nhầm file CSS và JavaScript: Đây là lỗi nghiêm trọng. Nếu Googlebot không thể truy cập các file này, nó sẽ không thể “nhìn thấy” website của bạn đúng cách, dẫn đến xếp hạng kém. Hãy đảm bảo bạn không
Disallowcác thư mục chứa CSS/JS. - Sai đường dẫn hoặc tên file: Chỉ cần một lỗi chính tả trong đường dẫn (ví dụ
/wp-adminthay vì/wp-admin/) cũng có thể khiến quy tắc không hoạt động. Hãy kiểm tra thật kỹ. - Sử dụng sai lệnh: Nhầm lẫn giữa
DisallowvàAllowcó thể gây ra hậu quả không lường trước được.
Một số lưu ý quan trọng khi tối ưu robots.txt
- Mỗi website chỉ có một file robots.txt duy nhất.
- File phải được đặt ở thư mục gốc.
- Không dùng robots.txt để che giấu thông tin nhạy cảm. File này công khai, ai cũng có thể xem. Hãy dùng các phương pháp bảo mật khác.
- Luôn khai báo sitemap ở cuối file để giúp bot tìm thấy nội dung của bạn dễ dàng hơn.

Kết luận
Qua bài viết này, WiWeb hy vọng bạn đã hiểu rõ robots.txt là gì và vai trò không thể thiếu của nó trong SEO. Dù chỉ là một tệp văn bản nhỏ, việc cấu hình đúng cách sẽ giúp bạn kiểm soát cách công cụ tìm kiếm tương tác với website, tối ưu ngân sách thu thập dữ liệu và bảo vệ những nội dung không cần công khai. Đừng xem nhẹ “người gác cổng” quyền lực này nhé.
Bạn còn thắc mắc nào về cách tạo file robots.txt chuẩn SEO không? Hãy chia sẻ với WiWeb ở phần bình luận nhé!
Nếu bạn đang tìm kiếm một giải pháp website chuyên nghiệp và được tối ưu SEO ngay từ nền tảng, đừng ngần ngại liên hệ với WiWeb. Chúng tôi luôn sẵn sàng đồng hành cùng bạn.







Mình đang dùng WordPress và thấy bài có nhắc đến plugin SEO tạo robots.txt ‘ảo’. Vậy theo kinh nghiệm của WiWeb, có plugin WordPress nào giúp tạo/chỉnh sửa robots.txt file vật lý một cách dễ dàng và đáng tin cậy không, hay mình cứ nên up thủ công qua FTP là an toàn nhất?
Chào bạn, rất vui vì câu hỏi của bạn! Theo kinh nghiệm của WiWeb, việc upload file robots.txt vật lý qua FTP/cPanel vẫn là cách đáng tin cậy nhất để đảm bảo hoạt động ổn định. Mặc dù một số plugin SEO có thể giúp chỉnh sửa robots.txt “ảo”, nhưng để có quyền kiểm soát tối ưu và chắc chắn nhất, cách thủ công luôn là lựa chọn ưu tiên bạn nhé.